 Download:
Download:




-
The dietary survey evaluated energy and nutrient intake of individuals and groups by collecting food intake data of respondents within a certain period. Traditional dietary survey methods commonly used in large-scale nutrition surveys and monitoring domestically and internationally include food frequency questionnaires (1–3) and food-weighing accounting methods combined with 24-hour dietary recall (4–5). At the current stage, traditional dietary surveys face issues such as large recall bias, complex data processing procedures, and a heavy burden on surveyors.
Large language models (LLMs) are artificial intelligence (AI) technologies based on deep learning. In recent years, LLMs have experienced rapid development from theoretical breakthroughs to applications (6–7). These models exhibit strong capabilities in contextual understanding, knowledge, reasoning, and text generation. In particular, large multimodal models that emerged after 2020 have realized the joint modeling of multidimensional data, such as text, images, and speech, providing technical support for complex scene applications (8). These technological breakthroughs have provided new solutions for complex text processing in the medical and healthcare fields. The innovative development of LLMs has provided a breakthrough approach for dietary surveys.
This study intends to conduct semantic recognition and data information structure research on 24-hour dietary survey text information based on LLM and explore the feasibility of AI in improving efficiency and assisting the investigators in completing the dietary surveys.
HTML
-
The study subjects were recruited from 15 families in the Huangpu and Jiading districts of Shanghai. In total, 38 individuals (86 person-times) completed the 24-hour dietary recall survey between October and November 2024.
-
Referring to standardized logic and asking for a 24-hour dietary recall method of a 24-hour dietary survey, the investigators used a computer-assisted dietary survey interviewing system to conduct a face-to-face dietary survey at home. The survey included questions regarding food and beverage intake by the participants in the past 24 h, including meal time, food/ingredient name, consumption, edible part, dining, and production location. Simultaneously, an intelligent recording pen (SR101T, iFLYTEK Co., Ltd.) recorded the interview process and transcribed it into text, which was then used for text recognition and data structuring with the LLM.
-
We used GLM-4 to generate the structured data. GLM-4 is a fourth-generation base large model released by Zhipu AI (Beijing Zhipu Huazhang Technology Co., Ltd.) on January 16, 2024. The dietary survey text data processing constructed in this study covers the following core steps: First, data cleaning, preprocessing, and de-identification were conducted on the recorded text of the on-site dietary survey to ensure data quality and compliance. Second, we combined two key technologies: prompt engineering and chain-of-thought prompts. Finally, the structured output was generated. We designed a complete quality control process, including a logic consistency check, statistical alignment analysis of results and manual annotations, and error analysis (Figure 1).
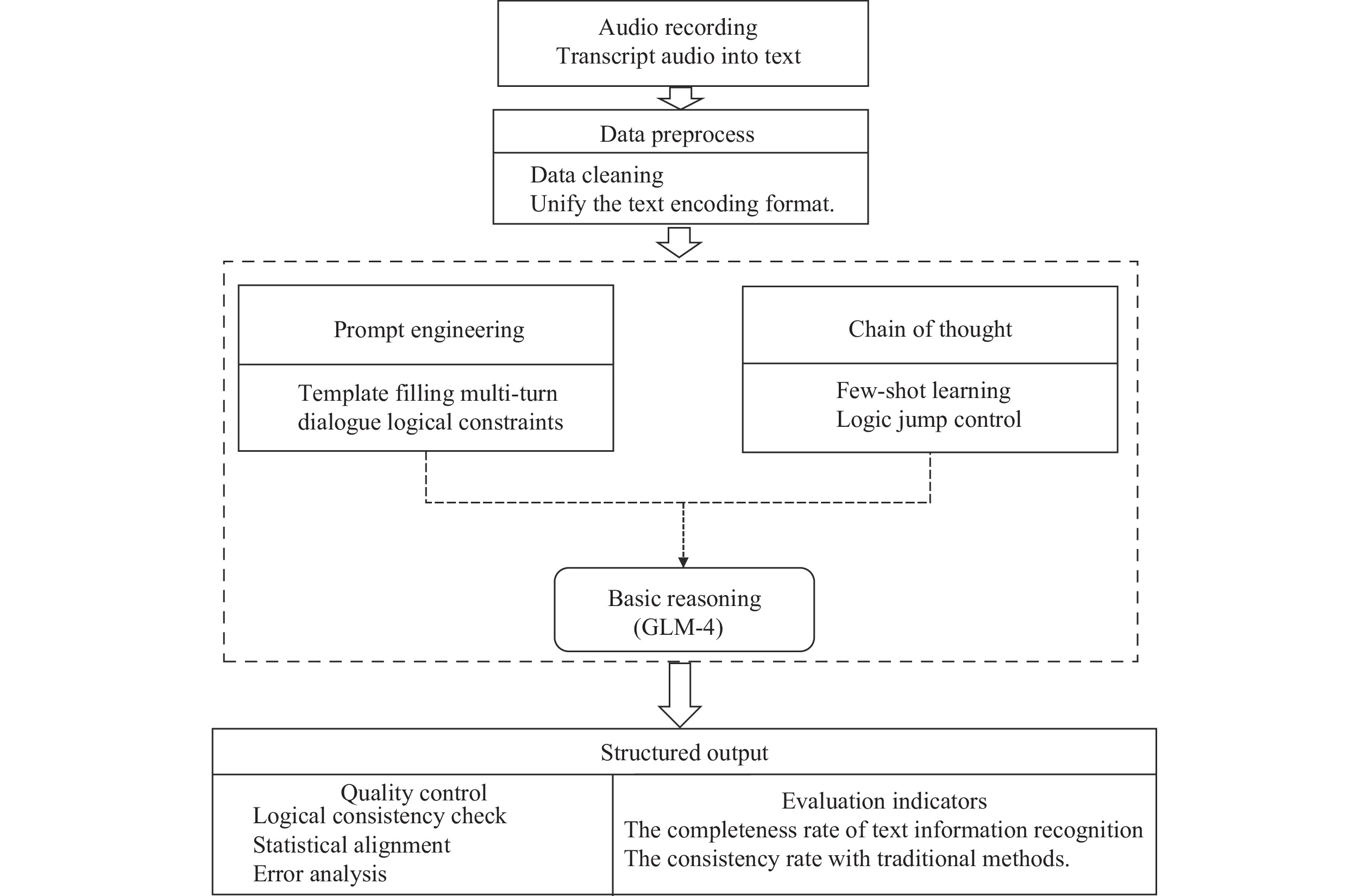 Figure 1.
Figure 1.Flowchart of text information recognition and data structuring based on LLM.
-
The dietary survey data collated and uploaded to the server by the investigator were downloaded and analyzed to describe the basic situation of the research object. The structured dietary data output by the LLM was compared with the dietary survey recording text, and the integrity of the LLM in the identification of key information was analyzed, such as whether the text mentioned “Mealtime” and the LLM recognized and produced effective structured data of “Mealtime.” Using the transcripts with complete identification information, the dietary data structured by the LLM were compared with those collated and uploaded by the investigator, and the consistency between the two methods in assigning key variables was analyzed.
Study Population
Dietary Data Collection Methods and Processing
Text Information Recognition and Data Structuring of LLM
Statistical Analysis
-
Thirty-eight family members from 15 households participated in the dietary survey and provided complete dietary survey data for 1–3 days, with a total of 86 person-day recalls, as shown in Table 1. Among them, children and adolescents under 18 years accounted for 7.9%, adults aged 18–59 years for 57.9%, and older adults aged 60 years and above for 34.2%. The respondents were primarily female, accounting for 63.2% of the sample.
Characteristics Jiading district Huangpu district Total Household survey, N (%) 6 (40.0) 9 (60.0) 15 Individuals, N (%) 15 (39.5) 23 (40.5) 38 person-times, N (%) 35 (40.7) 51 (59.3) 86 Age group, % <18 years 6.7 8.7 7.9 18–59 years 73.3 47.8 57.9 ≥60 years 20.0 43.5 34.2 Gender, % Male 46.7 30.4 36.8 Female 53.3 69.6 63.2 Table 1. Basic characteristics of the survey participants involved in the dietary survey.
-
Table 2 shows that the integrity of key information recognition using the LLM for dietary survey recording text was generally high, with an overall integrity rate of 92.5%. Among them, the recognition integrity rate for “Mealtime” and “Dining location” were the highest reaching 100%. The second is the recognition integrity rate for “Food name,” “Ingredient name,” and “Production location”, with recognition integrity rate above 90%. In contrast, the text recognition of “Consumption weight” and “edible or includes nonedible” was slightly lower, with the integrity rate of information extraction is 80%–86%.
Survey indicators Jiading district, % Huangpu district, % Total, % Mealtime 100.0 100.0 100.0 Food name 95.0 96.0 95.5 Ingredient name 93.0 92.0 92.5 Consumption weight 85.0 84.0 84.5 Edible or includes nonedible 86.0 80.0 83.0 Dining location 100.0 100.0 100.0 Production location 92.0 89.0 90.5 Overall integrity rate 93.0 92.0 92.5 Abbreviation: LLM=large language model. Table 2. Recognition integrity rate of dietary survey text information using LLM.
-
Table 3 further analyzes the consistency between the results of structuring the dietary survey data assisted by LLM and the data uploaded by traditional investigators. The results show that the overall consistency rate between the automatically structured data of the dietary survey recording text using the LLM and the data recorded and decomposed by traditional investigators is 86%. From the perspective of different survey indicators, the higher consistency rates are “Mealtime”, “Dining location,” and “Production location,” and the agreement rate can reach more than 90%. The second is the agreement rate of “Food name” and “Ingredient name,” which can reach more than 80%. The indicators with a relatively lower consistency rate are “consumption weight” and “edible or includes nonedible,” ranging from 70% to 80%.
Survey indicators Jiading district, % Huangpu district, % Total Mealtime 99.0 99.0 99.0 Food name 83.0 94.0 88.5 Ingredient name 81.0 85.0 83.0 Consumption weight 78.0 77.0 77.5 edible or includes nonedible 70.0 73.0 71.5 Dining location 87.0 99.0 93.0 Production location 87.0 95.0 91.0 Overall consistency rate 83.0 89.0 86.0 Abbreviation: LLM=large language model. Table 3. Consistency rate between the structured data of the LLM-assisted dietary survey and the data of the traditional survey method.
-
We further evaluated the model using Pression and F1 scores, with the LLM achieving 94% precision and an F1 score of 89.7% on the full dataset. Table 4 presents the advantages and challenges of applying the LLM to nutritional surveys and our proposals to improve this method.
Survey phases Advantages Challenges Improvement direction Recording collection Nondisruptive collection, reducing the workload of investigators. There are dialect barriers in the transcription of recordings, and the scope of application needs to be improved. The investigator should double check the key information. Text recognition Automatically remove invalid conversations and improve the efficiency of identifying key information. There are certain limitations in the complex semantic recognition of quantitative or professional indicators, such as consumption amount, edible or includes nonedible food. Continuously train the text understanding ability, logical computing ability, and professional judgment ability of LLM, and improve their adaptability. Data structuring Automatically extract and assign key indicators, forming a structured database in real time, reducing the need for investigators to reorganize and input data manually. There is a lack of information about the exact amount of food or the breakdown of the amount of food consumed by multiple people in a household. There are also some omissions or misjudgments in the determination of commercially available products. Optimize the underlying architecture to provide the average weight or range of different portion sizes of common foods. Combine semantic understanding and logical computing to achieve quantitative functionality in different question and answer scenarios. Abbreviation: LLM=large language model. Table 4. Advantages and challenges of text recognition and structuring of dietary surveys using LLM.
Basic Information
Integrity of Text Recognition in LLM
Consistency Analysis of Structured and Traditional Dietary Survey Data Assisted by LLM
Advantages and Challenges of Text Recognition and Structuring of Dietary Surveys Assisted by LLM
-
Our study used a dialogue survey, recorded and transcribed the dialogue into text, and used LLM-based text recognition and structured data extraction. The structured data were then compared with manual recordings. The overall recognition integrity of the survey was approximately 92.5%. The recognition completeness for food types and ingredients was 95.5% and 92.5%, respectively. The consistency rate between LLM-assisted structured dietary survey data and data from the traditional survey method was 86%. The major discrepancies occurred in the identification of the consumption weight and the ability to distinguish between edible and nonedible parts. Responses to these two questions were vague. The intake amount is generally described using quantifiers or gestures, and further analysis is required to convert it into grams or milliliters. Distinction between edible parts and commercially available products is currently made via manual identification. Additional data training is required to establish a database for large models, and multidimensional data (such as images and videos) support should be combined to increase the accuracy of these two problems.
This method was implemented as an auxiliary tool for dietary surveys. With the advent of the AI, a revolution has occurred in the field of medical research. In large-scale population studies, there is a need to improve survey methods without increasing their complexity and cost, considering the convenience and universality of the methods. In the future, we will attempt to combine voice transcription and image recognition based on deep learning. Sun et al. developed a deep-learning-based image recognition model for food identification at the ingredient level to conduct health management for patients with diabetes (9). This approach can be further advanced by testing AI architectures on a limited number of large-scale food image and nutrition databases (10).
However, AI has not been widely applied to large-scale population surveys. In medical ethics, surveys using AI face many challenges, owing to aspects such as user privacy, data security, and explainability. China is also accelerating the introduction of a series of ethical review norms and measures, in the hope that AI can be fully applied under ethical conditions. We will continue to monitor developments in AI (artificial intelligence) technology ethics management and research the application of large AI models to a larger population.
In the long run, large models will drive paradigm changes in nutritional research. At the public health level, the LLM can be applied to nutrition, spanning smart and personalized nutrition, dietary assessment, food recognition and tracking, predictive modeling for disease prevention, and disease diagnosis and monitoring (11). With the development of deep-learning technology, a distributed learning framework can solve the data island problem and accelerate cross-institutional and cross-regional nutrition and health research collaborations.
-
The efforts of the Shanghai Center for Disease Control and Prevention and all participants and interviewers of this study.
-
Approved by the institutional review board of the National Institute for Nutrition and Health, China CDC (No: 2022-024), and all participants provided written informed consent before participation.
| Citation: |

|