 Download:
Download:




-
Severe fever with thrombocytopenia syndrome (SFTS) is an emerging infectious disease caused by the SFTS virus. Since the first confirmed case was reported in 2009 (1), most cases have been reported in northern and central China (2-3). The number of reported SFTS cases continues to rise, and the areas affected by the disease are expanding (4-5). Due to its high case-fatality rate and the possibility of pandemic spread, the World Health Organization included SFTS on its list of the top 10 infectious diseases needing immediate research attention (6). Although China has established a valuable infectious disease surveillance system to monitor and assess disease burden, the system cannot predict future trends or provide early warnings of outbreaks. Furthermore, the monitoring data obtained are often delayed. Consequently, there is an urgent need for a model to predict the number of SFTS cases in endemic regions.
As a tick-borne disease, the incidence of SFTS exhibits distinct time-series characteristics, referring to data points collected and recorded chronologically, typically at regular intervals. Specialized time-series analysis techniques are likely suitable for effectively modeling and forecasting SFTS incidence.
In this study, we utilized various time series algorithms based on historical data to predict the occurrence of SFTS in Hubei Province, one of the first provinces to report SFTS cases and a province with a high incidence of the disease in China (7). Predicting the number of SFTS cases in this region will provide important insights for developing prevention and control interventions.
-
The monthly number of SFTS cases in Hubei Province was obtained from the Public Health Science Data Center (
https://www.phsciencedata.cn/Share/ ). Data reported between January 2013 and December 2019 (84 data points total) were used for model training and development, while the remaining data from January to December 2020 (12 data points total) were used for external validity assessment. -
SARIMA model: Seasonal autoregressive integrated moving average (SARIMA) is an extension of autoregressive integrated moving average (ARIMA) that requires selecting hyperparameters for both the trend and seasonal elements of the time series. The formula for SARIMA is as follows:
$$ (1-B)^{d}\left(1-B^{s}\right)^{D} Y_{t}=\theta_{0}+\frac{\theta(B) \theta_{s}\left(B^{s}\right)}{\phi(B) \phi_{s}\left(B^{s}\right)} \varepsilon_{t} $$ (1) where Yt refers to the value of the time series at time t, θ0 is constant, εt is the white noise value at period t, and the parameters d and D represent the difference number and seasonal difference number, respectively. B is the backshift operator,
$\phi (B) $ is the autoregressive operator, and θ(B) is the moving average operator.$\phi_s (B^s) $ and$\theta _s (B^s)$ are the seasonal operators.Prophet model: The Prophet model provides a versatile treatment of trends, seasonality, and holiday effects. The trend component, g(t), is engineered to capture non-periodic changes in the time series. The foundational equation of the Prophet model is expressed as:
$$ y_{t}=g(t)+s(t)+h(t)+\varepsilon_{t} $$ (2) Where yt denotes the predicted value at time t, s(t) is the seasonality component, h(t) represents the impact of holidays or specific events on the time series, and εt is the error term accounting for aspects of the data not explained by the model.
XGBoost: eXtreme Gradient Boosting (XGBoost) iteratively constructs a series of short, basic decision trees. For a dataset with n examples and m features, a tree ensemble model in XGBoost predicts the output using K additive functions:
$$ \hat{y}_{i}=\sum_{k=1}^{K} f_{k}\left(x_{i}\right), f_{k} \in F $$ (3) Here,
$ \widehat{y} $ represents the predicted value for the ith sample, fk is a function corresponding to the kth tree, and F denotes the space of regression tree functions, with xi being the feature vector for the ith sample.To learn the set of functions used in the model, XGBoost minimizes the following regularized objective:
$$ L\left(\varphi \right)={\sum }_{i=1}^{n}l\left({y}_{i},\widehat{{y}_{i}}\right)+{\sum }_{k=1}^{K}\Omega \left({f}_{k}\right) $$ (4) In this equation,
$ l\left({y}_{i},\widehat{{y}_{i}}\right) $ is the loss function that quantifies the error between the observed and predicted data, and Ω(fk) is the regularization term that helps smooth the learned weights. This smoothing prevents overfitting and encourages the model to select simpler, more predictive functions. The regularization term is defined as:$$ \Omega(f)=\gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2} $$ (5) Where γ and λ are regularization parameters, T is the number of leaves in the tree, and wj represents the score on each leaf.
Bayesian optimization was used to select the optimal hyperparameters, with the objective function defined to maximize R2.
LSTM Networks: Long short-term memory (LSTM) networks incorporate a cell state that acts as a form of memory. The key feature of LSTM networks lies in their gating mechanism, which comprises three types of gates.
The input gate regulates the flow of new information into the cell state through a two-step process. First, a sigmoid function determines the necessary update values, represented by the equation:
$$ i_{t}=\sigma\left(W_{x_{i}} x_{t}+W_{h} h_{t-1}+b_{i}\right) $$ (6) The second step employs a tanh function to generate a vector of new candidate values that may be added to the state, given by:
$$ {\stackrel{~}{C}}_{t}=\mathit{tan}h\left({W}_{{x}_{C}}{x}_{t}+{W}_{{h}_{C}}{h}_{t-1}+{b}_{C}\right) $$ (7) Here, it is the activation of the input gate, and
$ {\stackrel{~}{C}}_{t} $ is the candidate vector for the cell state update.The forget gate determines which information from the cell state to retain or discard. It uses a sigmoid function to evaluate the importance of existing information in the cell state, defined by:
$$ f_{t}=\sigma\left(W_{x_{f}} x_{t}+W_{h_{f}} h_{t-1}+b_{f}\right) $$ (8) The activation vector ft indicates the extent to which past information should be forgotten or retained.
The output gate regulates the information sent to the subsequent layer. This gate functions in two stages. First, a sigmoid function determines which parts of the cell state are outputted, as shown by:
$$ o_{t}=\sigma\left(W_{x_{0}} x_{t}+W_{h_{g}} h_{t-1}+b_{0}\right) $$ (9) Then, the final output is calculated by multiplying this activation ot with the tanh of the cell state, resulting in:
$$ h_{t}=o_{t} \times \tanh \left(C_{t}\right) $$ (10) The output vector ht represents the information transmitted to subsequent layers or units in the network.
In the models described above, clipping, a data post-processing technique, was used to address unrealistic negative values in the results. A detailed explanation of each model is provided in
Supplementary Material . -
The predictive performance of the models was assessed using two indices: mean absolute error (MAE) and root mean squared error (RMSE), defined as follows:
$$ M A E=\frac{1}{n} \sum_{i=1}^{n}\left|y_{i}-\hat{y}_{i}\right| $$ (11) $$ R M S E=\sqrt{\frac{1}{n} \sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}} $$ (12) -
Descriptive statistics and time series modeling were conducted using Python (version 3.7; Python Software Foundation, Beaverton, OR, USA). The SARIMA, Prophet, XGBoost, and LSTM models were implemented using the statsmodels, fbprophet, scikit-learn, and Keras packages, respectively. A P<0.05 was considered statistically significant.
-
A total of 1,695 SFTS cases were reported in Hubei Province from January 2013 to December 2020, exhibiting clear seasonal characteristics. More cases were reported from April to August each year and fewer from December to February of the following year. Interestingly, a prominent peak occurred in June and a smaller peak in October (Figure 1).
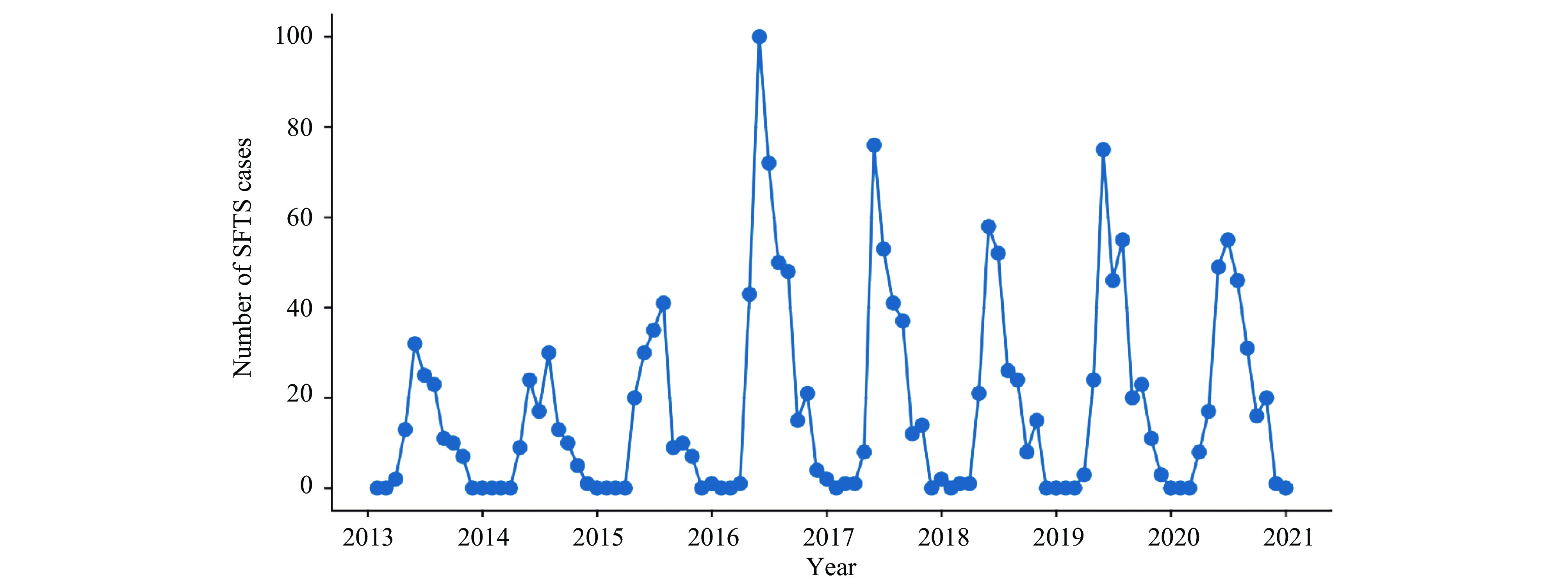 Figure 1.
Figure 1.Trends of the actual number of SFTS cases from January 2013 to December 2020 in Hubei Province, China.
Abbreviation: SFTS=Severe Fever with Thrombocytopenia Syndrome. -
In the SARIMA model construction, the augmented Dickey-Fuller (ADF) test indicated that the time series data were unstable with a P>0.05 (Dickey-Fuller=−1.339, P=0.611). After the first difference, the original sequence tended to become stationary. The parameters p and q were determined from the autocorrelation function (ACF) and partial autocorrelation function (PACF) plots (Figure 2), and the final model parameters were determined as SARIMA (1,1,1), (0,1,1)12 based on the minimum Akaike information criterion (AIC) (AIC=543.302). All parameters were significant with P<0.01 (
Supplementary Table S1 ). The residual autocorrelation test (Ljung-box test) indicated that the residual was not significantly different from a white noise series (Q-statistic=0.32, P=0.57), suggesting that the model was acceptable.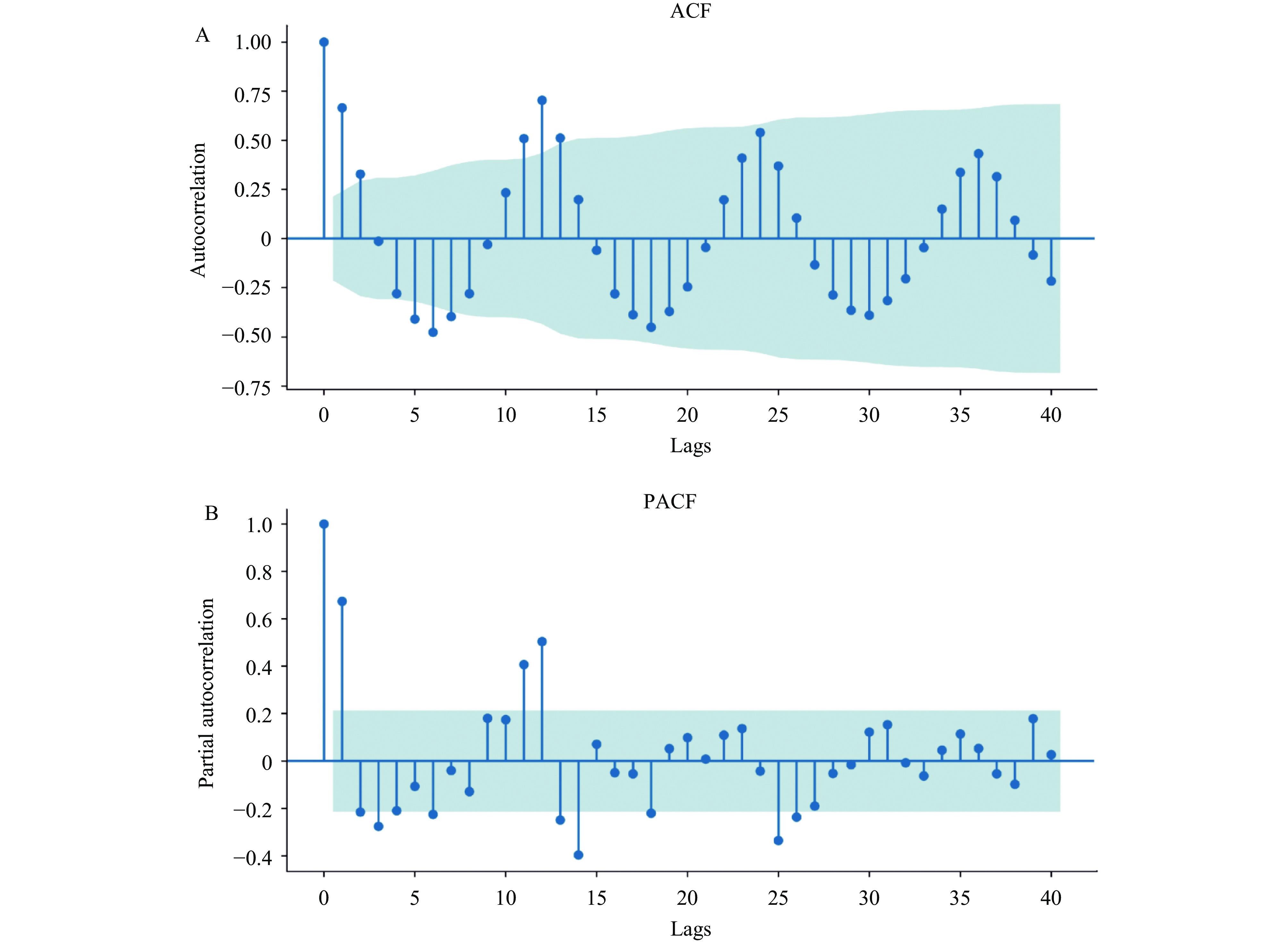 Figure 2.
Figure 2.ACF and PACF charts after the first-order difference. (A) ACF; (B) PACF.
Abbreviation: ACF=autocorrelation function; PACF=partial autocorrelation function.The optimized parameters of the other three models are summarized in Table 1.
Models Parameters Values Prophet Growth linear Seasonality mode additive Interval width 0.8 Changepoints 24 Changepoint prior scale 0.3 XGBoost Min_child_weight 9 Estimators 54 Learning rate 0.407 Max depth 6 LSTM No. of neurons 201 Layers 1 Learning rate 0.003 Activation tanh Recurrent activation sigmoid Dropout 0 Loss mse Optimizer Adam Batch size 1 Epochs 100 Table 1. Parameters of the optimized Prophet, XGBoost, and LSTM models.
-
The trained SARIMA, Prophet, XGBoost, and LSTM models were used to predict the number of reported SFTS cases in 2020 and were compared with real external validation data (Figure 3). All four models performed well in predicting the trends of SFTS cases; however, the XGBoost model yielded the closest fit to the actual case numbers (Figure 3). The prediction performances of the models were then compared using error indices, including MAE and RMSE. As shown in
Supplementary Table S2 , the MAE and RMSE of XGBoost were lower than those of the other three models, indicating that XGBoost performed best in predicting SFTS cases, followed by Prophet, LSTM, and SARIMA, respectively.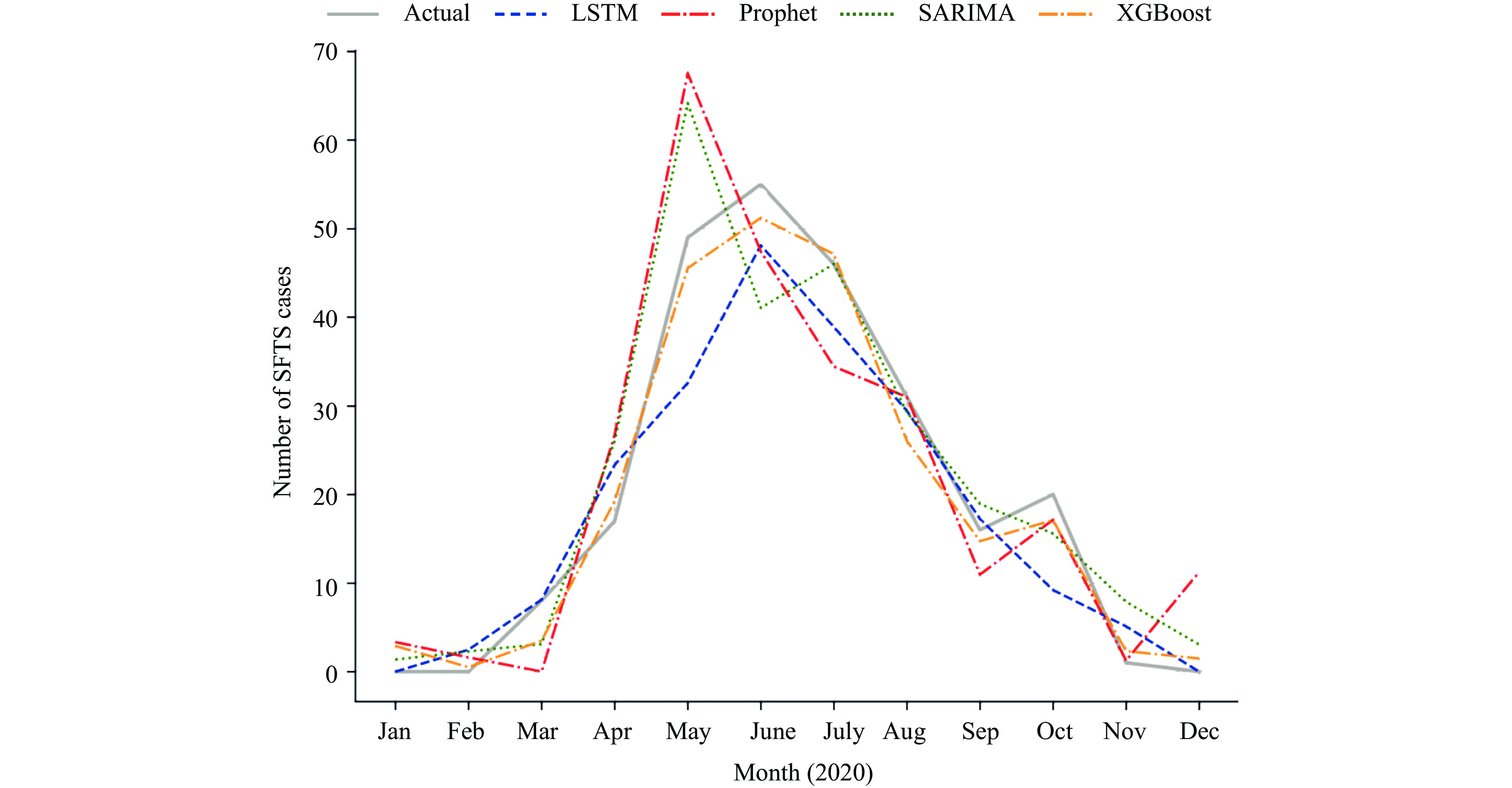 Figure 3.
Figure 3.Comparison of the actual SFTS cases with the predicted cases from January to December 2020 by the four models.
Abbreviation: LSTM=long short-term memory; SFTS=severe fever with thrombocytopenia syndrome; SARIMA=seasonal auto-regressive integrated moving average; XGBoost=eXtreme Gradient Boosting. -
Previous studies have conducted multivariate modeling analyses to examine the risk factors associated with SFTS incidence in Hubei Province (7). However, to our knowledge, this study is the first to construct predictive models for the number of SFTS cases in Hubei Province.
In this study, we developed four models based on different algorithms to predict SFTS cases in Hubei Province. Each algorithm has advantages and disadvantages. SARIMA models are relatively simple, linear models capable of uncovering dynamic relationships between historical and predicted data. However, they require the original sequence to be stable before modeling and struggle to capture nonlinear relationships in the data. This limitation becomes evident when abrupt changes or nonlinear trends are present in the data, as SARIMA is less flexible in adapting to these complexities.
In contrast, the Prophet model does not require consideration of time series data stationarity and offers greater parameter adjustability, enhancing its flexibility. This model can automatically detect and handle outliers in the data, making it suitable for noisy or irregular datasets. It demonstrates rapid computation, making it appropriate for large datasets and real-time forecasting applications. Prophet has shown excellent performance in predicting various infectious diseases, including coronavirus disease 2019 (COVID-19) and hand, foot, and mouth disease (8-10).
XGBoost displays robustness in handling nonlinear time series data, excelling at forecasting extreme values. This is likely due to its ability to model complex relationships through boosting. LSTM features a memory unit for storing information across time steps, which is advantageous for modeling long-term dependencies. It accommodates varying input and output dimensions for both univariate and multivariate data. However, LSTM may struggle with predicting sudden changes due to its reliance on past data patterns, as seen in our study with the surge in cases from April to May 2020.
All four models performed well in predicting SFTS cases and exhibited similar trends to the actual case counts. XGBoost demonstrated the closest predictions to the actual values, with the lowest MAE and RMSE values. Notably, SARIMA, Prophet, and LSTM did not accurately predict the May case counts (Figure 3). Additionally, SARIMA and Prophet failed to predict the peak month, possibly due to the sharp increase in actual cases from April to May 2020, which may have introduced challenges in predicting such volatile data. XGBoost displayed excellent performance in forecasting extreme values (such as the prominent June peak and the smaller October peak) and capturing the overall trend.
Considering that meteorological, geographical, and human activity factors are considered risk factors for SFTS (11–13), incorporating additional related external variables could enhance the predictive model’s performance. Furthermore, studies have indicated that combining linear and nonlinear models may yield superior predictive performance compared to single models, such as SARIMA-Prophet (14) and SARIMA-LSTM (15), representing a potential avenue for improvement.
In addition, the best model in the present study was developed based on data from Hubei Province, so it may not be suitable for other regions. This limits the model’s general applicability. However, the study provides a feasible scheme for other regions to predict the disease.
In conclusion, we established and evaluated various time series models. The XGBoost model demonstrated the best predictive performance for forecasting monthly confirmed SFTS cases in Hubei Province. This model holds promise for providing valuable information and data for the early assessment of potential SFTS risks, which is crucial for developing early warning systems and formulating effective prevention and control measures.
HTML
Data Collection
Model Constructions
















Performance Evaluations


Software
General Analysis
Models
Model Evaluation and Comparison
| Citation: |

|