
 Download:
Download:




-
Introduction Large language models (LLMs) have demonstrated potential applications across diverse fields, yet their effectiveness in supporting field epidemiology investigations remains uncertain.
Methods We assessed six prominent LLMs (ChatGPT-o4-mini-high, ChatGPT-4o, DeepSeek-R1, DeepSeek-V3, Qwen3-235B-A22B, and Qwen2.5-max) using multiple-choice and case-based questions from the 2025 Zhejiang Field Epidemiology Training Program entrance examination. Model responses were evaluated against standard answers and benchmarked against performance scores from junior epidemiologists.
Results For multiple-choice questions, only DeepSeek-V3 (75%) exceeded the 75th percentile performance level of junior epidemiologists (67.5%). In case-based assessments, most LLMs achieved or surpassed the 75th percentile of junior epidemiologists, demonstrating particular strength in data analysis tasks.
Conclusion Although LLMs demonstrate promise as supportive tools in field epidemiology investigations, they cannot yet replace human expertise. Significant challenges persist regarding the accuracy and timeliness of model outputs, alongside critical concerns about data security and privacy protection that must be addressed before widespread implementation.
-
Field epidemiology investigation serves as a cornerstone of public health practice, proving essential for identifying risk factors and implementing effective control measures. Large language models (LLMs) have recently emerged as potentially transformative tools in this domain (1). Models such as ChatGPT and DeepSeek have demonstrated impressive capabilities in text generation, reasoning, and data analysis. These systems can interpret user commands and generate contextually appropriate responses, positioning LLMs as valuable support tools across diverse fields.
Previous research has primarily concentrated on clinical applications of LLMs, where they have shown promise in medical diagnosis, patient counseling, and medical record management (2). While these applications highlight the broad potential of LLMs, their effectiveness in supporting field epidemiology investigations remains uncertain. Field epidemiology investigation encompasses extensive knowledge domains, including clinical medicine, epidemiology, laboratory and behavioral sciences, laws and regulations, technical guidelines, and decision-making frameworks (3). The existing literature on LLMs in public health remains limited, with few studies specifically examining their role in field epidemiology investigations. Moreover, most research has been conducted in Western contexts, leaving the application of LLMs in field epidemiology investigations — particularly within Chinese-language environments — largely unexplored. Given the rapid advancement of artificial intelligence (AI) Plus initiatives, investigating how LLMs can assist epidemiological investigations carries significant practical importance.
This study addressed this knowledge gap by evaluating the performance of several leading LLMs in executing common field epidemiology investigation tasks. The research not only contributes to a broader understanding of LLM applications in public health but also provides valuable insights for developing AI-assisted tools for field epidemiology investigations in China.
We selected six leading large language models for evaluation: three reasoning models (ChatGPT-o4-mini-high, DeepSeek-R1, and Qwen3-235B-A22B) and three non-reasoning models (DeepSeek-V3, Qwen2.5-max, and ChatGPT-4o). ChatGPT-o4-mini-high and ChatGPT-4o are proprietary closed-source models, while the remaining four represent open-source alternatives. Our evaluation framework utilized questions from the 2025 Zhejiang Field Epidemiology Training Program entrance examination, with all materials reviewed by field epidemiology experts to ensure accuracy and clarity. A total of 35 junior field epidemiologists participated in the examination. The assessment comprised two components: multiple-choice questions testing foundational knowledge and case-based scenarios evaluating practical application skills. The multiple-choice section included 20 single-answer questions with five options each, covering core topics such as infectious disease surveillance and reporting, risk assessment, outbreak management protocols, and sample collection procedures. The case-based questions presented open-ended scenarios requiring sequential responses, with each subsequent question posed only after the model completed its previous answer. This approach simulates real-world outbreak response conditions and evaluates the models’ capacity to provide accurate, professional guidance on demand. All models were accessed on May 12, 2025, through their respective web interfaces using standardized Chinese-language prompts. Additional methodological details are available in the
Supplementary Material .For multiple-choice questions, we compared model responses against standard answers, awarding one point for each correct response (maximum score: 20 points). The case-based section contained four questions, with each response independently evaluated by two expert assessors. These evaluators scored responses against established criteria, including scientific accuracy, comprehensiveness, clarity of presentation, and contextual relevance. Each open-ended question carried a maximum score of 10 points.
For the multiple-choice questions, we calculated the proportion of correct answers for each LLM and compared these results with responses from junior epidemiologists. Statistical differences were assessed using binomial tests with p0=0.20 (LLMs versus chance) and bootstrap approaches (highest-scoring LLM versus junior epidemiologists). For the case-based questions, we computed Pearson’s r and Spearman’s ρ to evaluate the correlation between the two evaluators’ ratings. We conducted Friedman and Wilcoxon tests to examine score differences in the open-ended questions. All statistical analyses were performed using the “stats” package in R software (version 4.3.2, R Core Team, Vienna, Austria). Statistical significance was set at P≤0.05.
Figure 1 demonstrates the performance of each LLM on the multiple-choice questions. Among the 20 questions, DeepSeek-V3 and Qwen3-235B-A22B achieved the highest scores, with 15/20 [75%, 95% confidence interval (CI): 50.9%, 91.3%] and 13/20 (65%, 95% CI: 40.8%, 84.6%), respectively. ChatGPT-o4-mini-high and ChatGPT-4o obtained the lowest scores, both scoring 8/20 (40%, 95% CI: 19.1%, 63.9%). The results revealed that four models achieved accuracy rates significantly higher than random guessing (P<0.05), with the exceptions being ChatGPT-o4-mini-high and ChatGPT-4o. Additional results are provided in the supplementary materials (Figure S1 and Table S1). When comparing the top-performing model, DeepSeek-V3 demonstrated significantly better performance than the median accuracy rate of junior epidemiologists (60.0%) (P<0.05).
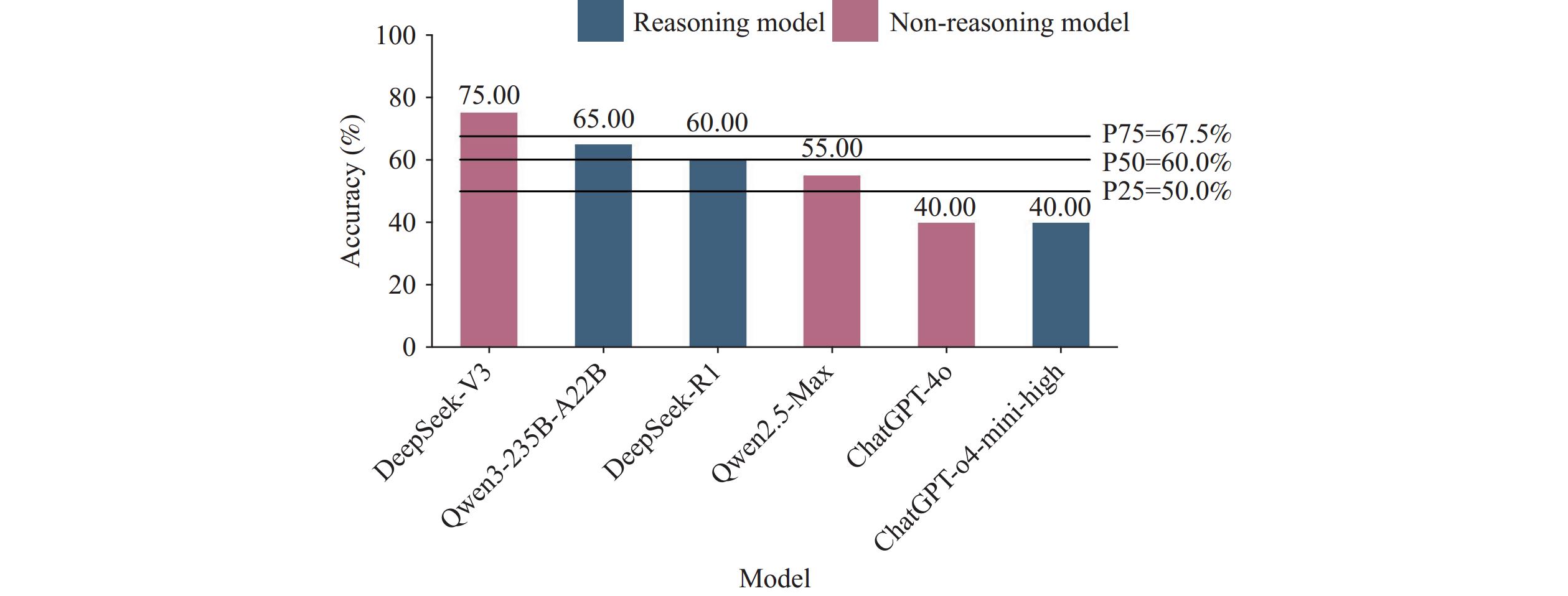 Figure 1.
Figure 1.Accuracy of each model in multiple-choice questions.
Table 1 demonstrates strong inter-rater reliability between the two experts in their evaluation of the case-based questions. Consequently, we utilized the average of both evaluators’ scores as the final assessment for each open-ended question.
Question Pearson correlation Spearman correlation r P ρ P Question 1 0.937 0.006 0.742 0.091 Question 2 0.859 0.028 0.857 0.029 Question 3 0.860 0.028 0.739 0.094 Question 4 0.970 0.001 0.953 0.003 Table 1. Correlation between scores assigned by two evaluators for responses provided by six large language models.
In the case-based section, performance varied across questions and models. For Question 1, DeepSeek-V3 achieved the highest score and was the only model to exceed the 75th percentile (P75) of junior epidemiologist scores. For Question 2, ChatGPT-4o demonstrated superior performance, while Qwen2.5 and DeepSeek-R1 both matched the P75 level of junior epidemiologists. For Question 3, four models — Qwen2.5, Qwen3-235B-A22B, DeepSeek-V3, and DeepSeek-R1 — all scored above the P75 level of junior epidemiologists, with Qwen2.5 achieving the highest score. For Question 4, all models except ChatGPT-o4-mini-high exceeded the P75 level of junior epidemiologists, with ChatGPT-4o demonstrating the strongest performance.
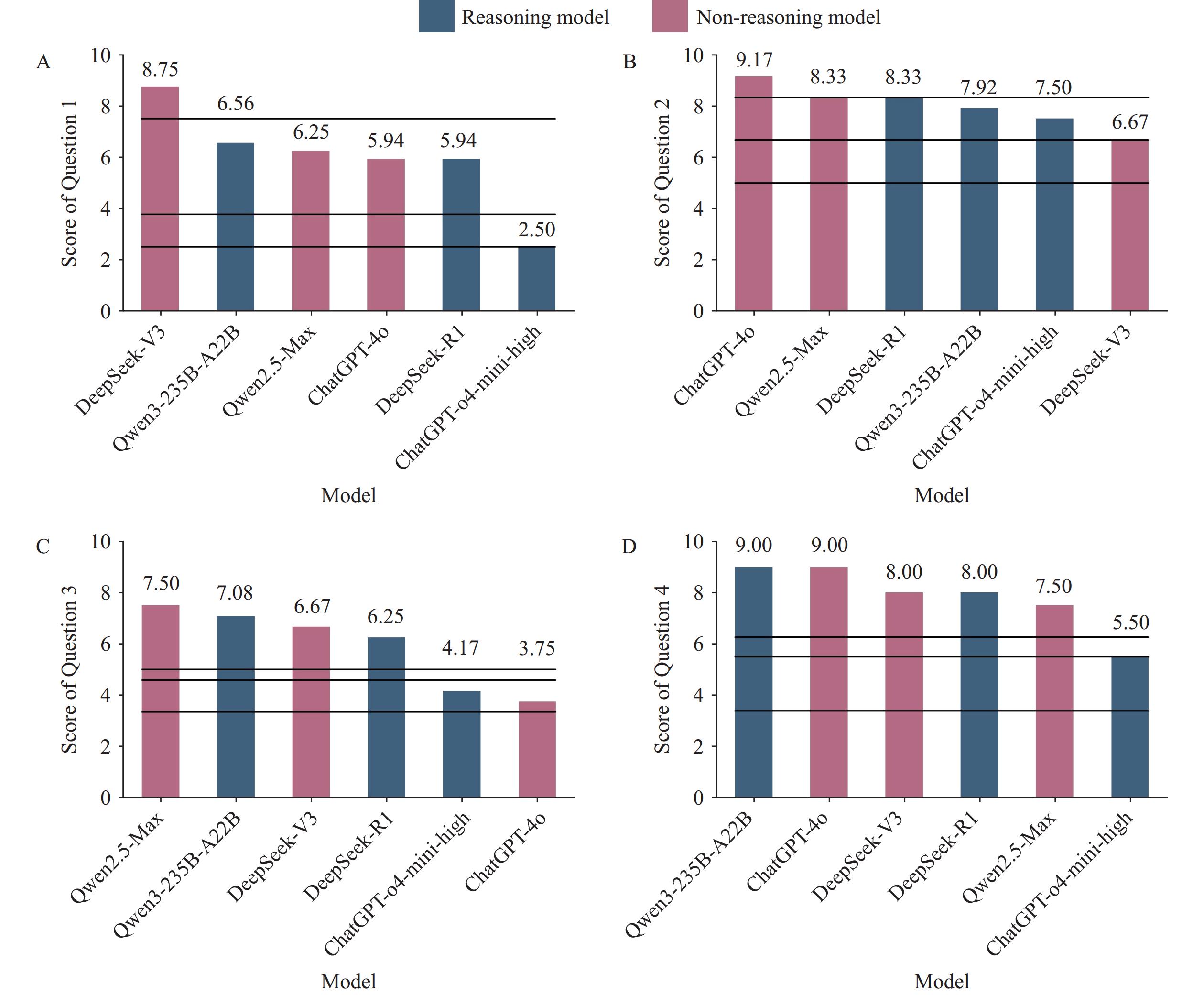 Figure 2.
Figure 2.The average scores for the answers to each open-ended question provided by the six large language models.
(A) Average Scores for Question 1; (B) Average Scores for Question 2; (C) Average Scores for Question 3; (D) Average Scores for Question 4.The chi-squared value from the Friedman test was 6.765, with a P of 0.239. Paired Wilcoxon tests revealed that the differences between ChatGPT-o4-mini-high and the other five models (DeepSeek-R1, P=0.11; DeepSeek-V3, P=0.11; Qwen3-235B-A22B, P=0.11, Qwen2.5-Max, P=0.10, ChatGPT-4o, P=0.34) were not statistically significant. All other pairwise comparisons yielded P greater than 0.5.
-
This study evaluated the capabilities of six currently popular LLMs in supporting field epidemiology investigations and compared their performance with examination scores from junior field epidemiologists. Among the multiple-choice questions, DeepSeek-V3 achieved the highest accuracy rate, followed by Qwen3-235B-A22B and DeepSeek-R1. For the case-based questions, no statistically significant differences were observed among the models overall; however, ChatGPT-o4-mini-high demonstrated relatively poor performance compared to the other models.
In this study, the Chinese-language LLMs (DeepSeek and Qwen) demonstrated superior performance compared to ChatGPT. The DeepSeek and Qwen models were developed using extensive Chinese language corpora during training, whereas ChatGPT was trained with limited Chinese-language content (4). Consequently, ChatGPT performed poorly on questions that relied heavily on Chinese language knowledge or cultural context. However, for tasks such as data analysis (Question 4), which are less dependent on Chinese-language training data, ChatGPT exhibited acceptable performance.
This study revealed that, for multiple-choice questions, most LLMs achieved lower accuracy rates than the 75th percentile level of junior field epidemiologists. Conversely, in the case-based questions, the overall performance of LLMs exceeded that of most junior field epidemiologists. Poor performance was particularly evident on Question 1, which involved professional prevention and control protocols for specific infectious diseases. This limitation may primarily stem from the absence of specialized knowledge resources in the LLMs (4). Similarly, the LLMs scored relatively low on Question 3, which addressed outbreak control measures. Their responses frequently included irrelevant or non-essential content, likely due to the same knowledge gap, resulting in answers that lacked technical precision and professional rigor.
Previous research has indicated that closed-source models may outperform their open-source counterparts (5). However, our findings demonstrate that the four Chinese open-source models generally exceeded ChatGPT’s performance, underscoring the substantial potential of open-source architectures. Open-source models offer the advantage of local deployment, providing enhanced data security — a feature of paramount importance for developing specialized LLMs tailored to public health institutions.
Our study also revealed that reasoning models did not demonstrate superior performance compared to non-reasoning models, a finding consistent with observations by Sandmann et al. (6). Through chain-of-thought prompting in the reasoning models, we observed that LLMs incorporate knowledge from various temporal periods within their training datasets. However, these models lack the capability to distinguish between outdated and current information, resulting in instances where they failed to provide the most up-to-date knowledge.
Nevertheless, the implementation of LLMs in field epidemiology investigations continues to face several significant challenges. A critical concern is that field epidemiology is intrinsically linked to disease prevention and control, which demands exceptional timeliness and accuracy in model outputs. Our investigation identified limitations regarding citation accuracy in LLM-generated responses. In the case-based questions, several LLMs referenced guidelines or technical documents that were entirely fabricated. This presents substantial risks for junior professionals who may depend on these models without possessing the expertise to identify such erroneous references. Furthermore, LLMs trained on public knowledge bases carry an inherent risk of data contamination, potentially compromising the reliability of their outputs. These limitations have been documented in the existing literature (7-8). We therefore strongly recommend that professionals exercise caution when utilizing LLMs, cross-reference their outputs against established trusted sources, and treat these models as supplementary tools rather than substitutes for individual knowledge and experience. To enhance model performance, developing specialized knowledge resources for LLMs will be essential, supported by high-quality, regularly updated datasets for training purposes.
Another critical challenge involves data security and privacy protection (9). Field epidemiology investigations frequently handle sensitive information, including patient privacy data and confidential government decision-making processes, all requiring robust protection measures. Without adequate safeguards, the practical implementation of LLMs could face severe limitations. To address these concerns, comprehensive regulatory frameworks will play an essential role. The European Union has already established relevant regulations through the EU AI Act, representing the world’s first comprehensive artificial intelligence legislation. In 2023, China also issued China’s Interim Measures for the Management of Generative AI Services. However, as an emerging technology, LLM governance and oversight require continued research and development to ensure both innovation advancement and safety assurance (10).
This study presents several limitations that warrant consideration. First, our evaluation was restricted to entrance exam questions from the Zhejiang Field Epidemiology Training Program, which may not comprehensively represent all aspects of field epidemiology investigations. Second, LLM outputs exhibit inherent stochasticity, meaning responses to identical prompts may vary across individual runs. However, existing research indicates that for knowledge-intensive tasks, while model performance may show sensitivity to minor prompt variations, it generally maintains relative stability overall. Finally, our evaluation employed a limited number of questions, with case-based scenarios focusing exclusively on infectious diseases. Consequently, model performance in other types of public health emergencies remains uncertain. Future studies should expand the evaluation scope to enhance the reliability and generalizability of these findings.
This study evaluated the potential of six leading LLMs to support field epidemiology investigations by comparing their performance against junior field epidemiologists’ examination scores. Our findings demonstrate that several models achieved notable accuracy and relevance across both multiple-choice and case-based assessments. However, current LLMs cannot yet replace human epidemiological expertise. While these models show promise as supplementary tools, their practical implementation faces significant challenges. Future development should prioritize integrating verified knowledge databases to optimize model performance and establishing robust regulatory frameworks to ensure their safe and effective application in public health settings.
HTML
| Citation: |

|